First make a little introduction to know what we are doing.
Image Compression
The objective of image compression is to reduce the redundant and irrelevant data of the image with the lowest possible loss, suitable for storage or transmission efficiently.
Classifying compression methods:
Methods lossy encoding:
Methods of lossless compression coding:
There are different ways to decompose an image, but in this case applies DWT, this wavelet transform has recently become a very popular tool when it comes to analysis, denoising and signal and image compression, this transform obtained of a image four types of ratios:Classifying compression methods:
- Lossless compression (Lossles).
- Lossy compression (lossy).
Methods lossy encoding:
- Lossy predictive coding.
- Transform Coding.
Methods of lossless compression coding:
- Variable logitud coding (Huffman Coding and others).
- Encoding bit planes: decomposition and RLE.
- LZW and CCYTT Basics.
- Lossless predictive coding.

- cA: Coefficient of approximation. (LL, which corresponds to the upper left corner)
- cH: horizontal detail coefficient. (LH, which corresponds to the upper right corner)
- cV: vertical detail coefficient. (HL, which corresponds to the lower left corner)
- cD: diagonal detail coefficient. (HH, which corresponds to the lower right corner)
What are wavelets?
The wavelets are families of functions found in space and used as features for analysis, examine the signal of interest for its features and address space size.
Wavelets
Until now, the major outstanding application of wavelets has been digital image compression. They are the backbone of the new standard JPEG-2000 digital imaging and method WSQ (Wavelet Scalar Quantization English, wavelet scalar quantization) using the FBI to compress its database of fingerprints. In this context, one can think of wavelets as basic components of the images. An image of a forest may consist wider wavelets: a large swath of green for the forest and a patch of blue for the sky. Wavelets greater detail and sharpness can be used to distinguish one another tree. You can add branches and needles wavelet image even finer. As a brushstroke of a painting, each wavelet is not an image itself, but many wavelets together can recreate anything. Unlike a stroke of a painting, a wavelet can be made arbitrarily small: one wavelet has no physical limitations of size because it is just a series of zeros and ones stored in the memory of http://www7.nationalacademies.org/ spanishbeyonddiscovery/mat_008276-04.htmluna computer.
A fascinating property of wavelets is to automatically choose the same features as our eyes. The wavelet coefficients after quantization are still correspond to pixels that are very different from their neighbors, on the edge of objects in an image. Thus, wavelets recreate an image by tracing edges mainly, that is exactly what humans do when they paint a picture. In fact, some researchers have suggested that the analogy between wavelet transformation and human vision is not accidental, and that our visual cues filtered neurons similarly to wavelets.
Some types of wavelets for compression
- Haar wavelets
The first DWT was invented by the Hungarian mathematician Alfréd Haar. For an input represented by a list of
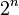 numbers, the Haar wavelet transform may be considered to simply pair up input values, storing the difference and passing the sum. This process is repeated recursively, pairing up the sums to provide the next scale: finally resulting in
numbers, the Haar wavelet transform may be considered to simply pair up input values, storing the difference and passing the sum. This process is repeated recursively, pairing up the sums to provide the next scale: finally resulting in 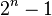 differences and one final sum.
differences and one final sum.- Daubechies wavelets
The most commonly used set of discrete wavelet transforms was formulated by the Belgian mathematician Ingrid Daubechies in 1988. This formulation is based on the use of recurrence relations to generate progressively finer discrete samplings of an implicit mother wavelet function; each resolution is twice that of the previous scale. In her seminal paper, Daubechies derives a family of wavelets, the first of which is the Haar wavelet. Interest in this field has exploded since then, and many variations of Daubechies' original wavelets were developed.
- The Dual-Tree Complex Wavelet Transform (ℂWT) The Dual-Tree Complex Wavelet Transform (ℂWT) is relatively recent enhancement to the discrete wavelet transform (DWT), with important additional properties: It is nearly shift invariant and directionally selective in two and higher dimensions. It achieves this with a redundancy factor of only
 for d-dimensional signals, which is substantially lower than the undecimated DWT. The multidimensional (M-D) dual-tree ℂWT is nonseparable but is based on a computationally efficient, separable filter bank (FB).
for d-dimensional signals, which is substantially lower than the undecimated DWT. The multidimensional (M-D) dual-tree ℂWT is nonseparable but is based on a computationally efficient, separable filter bank (FB).What was used?
- Wavelets.
- A type of Fourier transform (DWT as mentioned above).
- Python as programming language.
- PyWavelets library to call the transformed and so compress the image.
- Libreria numpy to make a matrix with the pixels of the image and so is easier to implement the wavelet.
- PIL library for image loading.
- Library for execution sys from commands in terminal.
- Library time, to know execution times.
Sequence
The sequence following the code is simple thanks to the libraries used
- Image is loaded.
- We make the image smaller, to make the process faster.
- Then we put a grayscale filter to the image.
- Then we take the pixels as an array with numpy.
- We use the discrete transform for compression.
- We save image.
Code
Results
______________________________________________________________________
_______________________________________________________________________________
Results
 |
| Original image |
 |
| Compress image |
| Comparison of weights |
| Times |
 |
| Original image |
 |
| Compress image |
| Comparison of weights |
| Times |
 |
| Original image |
 |
| Compress image |
| Comparison weight |
| Times |
Conclusion
The discrete transform works great for compressing images and we can notice in the above results, this is very good because as mentioned above have files lighter help us to store more information. Unfortunately the images come out very blurry
The image size affects the time that is done the compression process as it has to do more tours of the image.
References
[*] wavelets: ver el bosque y los arboles, Beyond discovery, http://www7.nationalacademies.org/spanishbeyonddiscovery/mat_008276-04.html
[*]Compresión de imagen, Wikipedia la enciclopedia libre http://es.wikipedia.org/wiki/Compresi%C3%B3n_de_imagen
[*]nullege http://nullege.com/codes/show/src@p@y@PyWavelets-0.2.2@demo@wp_2d.py/10/pywt.WaveletPacket2D
[*] http://hci.iwr.uni-heidelberg.de/MIP/Teaching/ip/ex04/ia_ex04.pdf
[*] Documentation pywavelets http://www.pybytes.com/pywavelets/ref/wavelets.html
[*] DWT. http://www.pybytes.com/pywavelets/ref/dwt-discrete-wavelet-transform.html
































